TL;DR:
- Search engine indexing involves search engines like Google discovering and storing web pages to enable quick retrieval. Without proper indexing, your content remains invisible in search results, making SEO efforts ineffective. Maintaining technical health, updating sitemaps, and ensuring correct structured data are essential for consistent indexing and ranking success.
Search engine indexing is defined as the process by which search engines like Google fetch, parse, and store web pages into a massive structured database called an index, enabling fast and accurate retrieval of results for any user query. Without this process, your content simply does not exist in search. Google’s index alone contains over 50 billion pages, a scale that illustrates just how critical indexing infrastructure is to modern search. For website owners and digital marketers, understanding indexing is not optional. It is the foundation every SEO strategy is built on.
Search engine indexing works in three distinct phases: crawling, parsing, and storing. Each phase determines whether your page makes it into the index or gets dropped entirely.
Crawling is the discovery phase. Automated programs called bots or spiders, most notably Googlebot, move across the web by following links and reading XML sitemaps. They request pages the same way a browser does, then pass that raw data to the next phase.
Parsing is where the real analysis happens. The search engine reads your content, metadata, heading structure, image alt text, canonical tags, and structured data markup. Signals like canonical tags and structured data are evaluated during this phase to understand what the page is about and which version should be treated as authoritative. Pages with thin content, duplicate text, or confusing signals often fail here.

Storing is the final step. Pages that pass quality and uniqueness checks are written into the index. Those that fail are dropped. A page can be crawled but not indexed due to content quality or technical issues, which is one of the most common and overlooked problems in SEO.
The technical backbone of all this is the inverted index. Think of it like the index at the back of a textbook. Instead of organizing pages by their content, the inverted index maps unique words to documents that contain them, along with frequency and position data. When you type a query, the search engine intersects these word maps in milliseconds to return relevant results. Without the pre-built index, performing real-time searches across the live web would be computationally impossible.
Pro Tip: Submit your XML sitemap directly in Google Search Console to accelerate discovery. Bots will still find your pages organically, but a sitemap removes guesswork and speeds up the crawl cycle significantly.
Indexing is a binary state. A page is either in the index or it is not. Ranking depends on 200+ signals, but none of those signals matter if the page was never indexed in the first place. This is the most fundamental fact in search engine optimization, and it is the one most often skipped over in favor of discussing keywords and backlinks.
For cannabis businesses and regulated-industry sites, this matters even more. Platform restrictions and compliance requirements can create technical configurations that accidentally block crawlers. A single misplaced directive in a robots.txt file can prevent Googlebot from accessing your entire site.
Here are the technical SEO factors that most directly affect whether your pages get indexed:
SEO results typically take months to appear after a page is crawled and indexed. That delay makes it even more important to resolve indexing issues early rather than waiting to see whether traffic materializes.
Pro Tip: Use the URL Inspection tool inside Google Search Console to check whether a specific page is indexed. It shows the last crawl date, indexing status, and any detected issues. Run this check on your highest-priority pages every quarter.
Not all indexes work the same way. Understanding the differences helps you make smarter decisions about structured data, metadata, and content architecture.
| Index type | How it works | Best for | Limitation |
|---|---|---|---|
| Inverted index | Maps words to documents containing them | Fast keyword-based retrieval | Less effective for semantic or contextual queries |
| Forward index | Maps documents to the words they contain | Building and updating the index | Too slow for real-time query matching |
| Semantic index | Maps concepts and entity relationships | Understanding intent and context | Requires significant computational resources |
| Metadata index | Stores structured attributes like author, date, and schema | Filtering and rich result generation | Depends on accurate markup from the publisher |
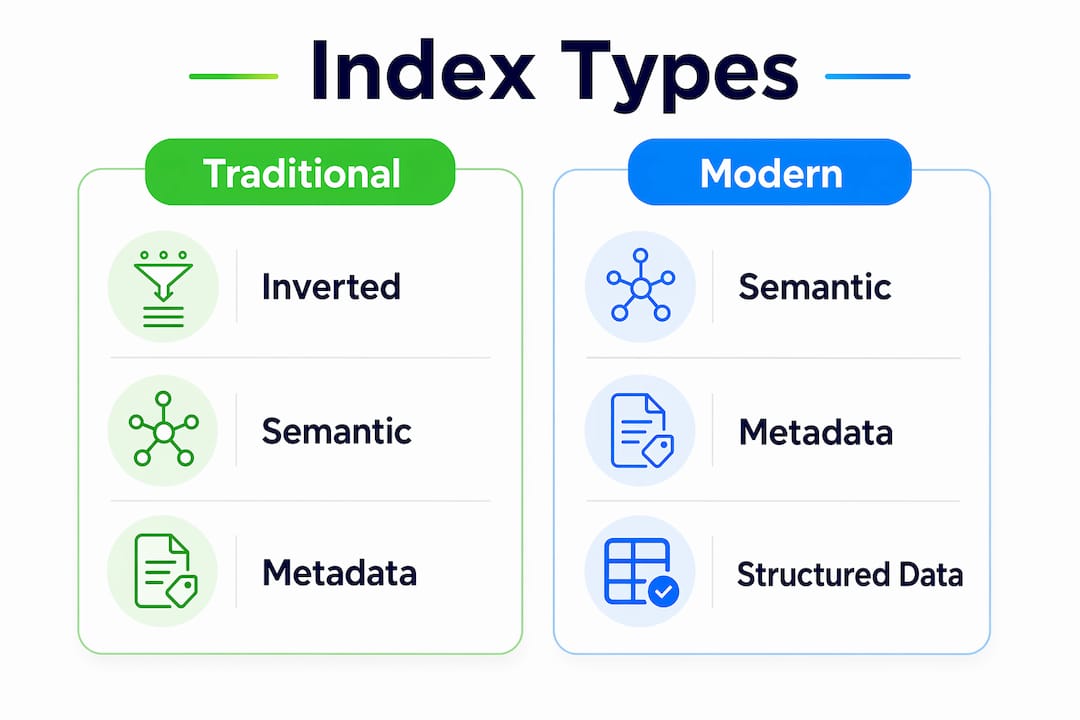
The inverted index is the workhorse of traditional search. The semantic index is where modern search engines like Google have invested heavily, particularly as AI integration reshapes how queries are interpreted. Core SEO principles remain foundational despite generative AI; indexing and ranking systems are still central to how results are delivered.
Structured data markup, specifically Schema.org vocabulary, feeds the metadata index and increases your chances of appearing in rich results like featured snippets, knowledge panels, and product carousels. For cannabis dispensaries, this means marking up your menu items, business hours, and location data correctly so Google can store and surface that information accurately.
Getting indexed is not a one-time task. Indexing is a living database that requires ongoing content updates and technical maintenance to keep pages relevant and visible. Here is what you should be doing consistently:
For regulated industries like cannabis, SEO compliance practices add another layer to indexing management. You need to balance what search engines can access with what your compliance requirements allow to be publicly visible.
Search engine indexing is the non-negotiable first step in SEO: a page that is not indexed cannot rank, regardless of its content quality or backlink profile.
| Point | Details |
|---|---|
| Indexing is binary | A page is either in the index or it is not. No index presence means no search visibility. |
| Crawling does not guarantee indexing | Quality, uniqueness, and technical factors during parsing determine actual inclusion. |
| Inverted index enables fast search | Word-to-document mapping allows near-instant query matching across billions of pages. |
| Technical SEO drives indexability | Site speed, mobile-friendliness, and clean internal links directly affect crawl and index outcomes. |
| Ongoing maintenance is required | Regular content updates, sitemap management, and crawl error fixes keep pages indexed and visible. |
After working with cannabis businesses and regulated-industry sites for years, the pattern I see most often is this: the indexing problem was created by the site owner, not by Google. A developer adds a noindex tag during staging and forgets to remove it at launch. A compliance update blocks an entire subdirectory in robots.txt. A site migration creates thousands of broken internal links that never get fixed.
Google is not the obstacle in most cases. The obstacle is a lack of systematic technical auditing. Most cannabis dispensary sites I review have at least three to five indexing issues that have been sitting undetected for months. The pages exist, the content is solid, but nothing ranks because the technical foundation was never checked after the site went live.
The trend I am watching closely in 2026 is the growing weight of structured data in indexing decisions. As Google’s AI-driven search features expand, the metadata index becomes more important. Sites that mark up their content with accurate Schema.org vocabulary are giving Google richer signals to work with, and that translates directly into better indexing outcomes and more frequent appearances in AI-generated summaries.
My advice is straightforward: treat indexing as infrastructure, not a one-time setup. Schedule quarterly technical audits, monitor Google Search Console weekly, and make structured data a standard part of every content publish. The sites that do this consistently outperform those that treat SEO as a campaign rather than an ongoing operation.
For cannabis brands navigating technical SEO for legal and compliance-sensitive content, this discipline is even more critical. One misconfigured directive can wipe out months of ranking progress.
— Max

If your dispensary or cannabis brand is publishing content that is not showing up in search results, the problem is almost always rooted in indexing. Dopeseo specializes in technical SEO for cannabis businesses, including full indexing audits, sitemap management, structured data implementation, and crawl error resolution. The team at Dopeseo understands the compliance constraints and platform restrictions that make cannabis SEO uniquely challenging. Whether you are a dispensary, cultivator, or ancillary brand, cannabis SEO services from Dopeseo are built to get your pages indexed, ranked, and driving organic traffic from customers who are actively searching for what you offer.
Search engine indexing is the process of storing web page data in a structured database so search engines can retrieve relevant results instantly. Without indexing, your pages cannot appear in search results.
Crawling is the discovery phase where bots visit pages. Indexing is the storage phase where pages that pass quality checks are added to the search database. A page can be crawled but still not indexed.
Indexing timelines vary, but new pages on established sites are typically crawled within days. SEO ranking impact from newly indexed pages generally takes weeks to months to materialize.
Pages are excluded from the index due to thin content, duplicate content, noindex tags, or technical issues detected during parsing. Google Search Console’s Coverage report identifies the specific reason for each excluded URL.
Use the URL Inspection tool in Google Search Console to check the indexing status of individual pages. You can also search site:yourdomain.com in Google to see a rough count of indexed pages.
© 2026 Curious Monkeys Pressing Buttons LLC DBA Cannabiz Marketing Solutions AKA DopeSEO. All rights reserved.